Запросы к данным о посещении Web-сайтов
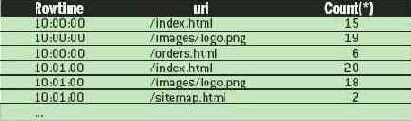
Предположим, что нам требуется отслеживать наиболее популярные страницы некоторого Web-сайта. При каждом обращении пользователей к Web-серверу генерируется запись в журнальном файле, содержащая данные о времени, URI данной страницы и IP-адресе обращающегося пользователя. Некоторый адаптер может непрерывно анализировать журнальный файл и образовывать поток записей. Показанный ниже запрос вычисляет число запросов в минуту к каждой странице Web-сайта. Возможные результаты приведены в табл. 1.
SELECT STREAM ROWTIME, uri, COUNT(*) FROM PageRequests GROUP BY FLOOR(ROWTIME TO MINUTE), uri;
Таблица 1
В этом примере, как и в других примерах данной статьи, для формулировки запроса используется язык запросов SQLstream. Этот язык является стандартным языком SQL с несколькими потоковыми расширениями [4]. Другие системы обработки запросов к потоковым данным обладают аналогичными возможностями.
Единственными расширениями SQL, используемыми в данном запросе, являются ключевое слово STREAM и системный столбец ROWTIME. Если убрать из запроса ключевое слово STREAM и преобразовать PageRequests в таблицу со столбцом ROWTIME, то полученный запрос можно было бы выполнить в традиционной СУБД, такой как Oracle или MySQL. При выполнении такого запроса анализировались бы все обращения к страницам Web-сайта, произведенные до настоящего времени. Однако если PageRequests является потоком, то ключевое слово STREAM указывает системе на необходимость подсоединиться к этому потоку и применять операцию ко всем будущим записям.
Каждую минуту этот запрос генерирует набор записей, подытоживающих трафик на каждой странице в течение этой минуты. Результирующие строки с временной меткой 10:00:00 подытоживают все обращения, произошедшие между моментами времени 10:00 и 10:01(включая 10:00 и не включая 10:01). Строки в потоке PageRequests упорядочиваются по значениям системного столбца ROWTIME, так что результирующие строки с временной меткой 10:00:00 буквально выталкиваются при поступлении первой строки с временной меткой 10:01:00 или более поздней. Система обработки запросов к потоковым данным обычно обрабатывает данные и доставляет результаты только при поступлении новых данных, так что можно сказать, что она работает "под давлением" данных. Это отличается от подхода "вытягивания" данных, применяемого в реляционных СУБД, где приложения должны постоянно опрашивать систему для получения новых результатов.
В следующем примере находятся URI, для которых число обращений больше обычного. Сначала представление PageRequestsWithCount вычисляет число обращений за последний час к каждому URI и их среднее значение за последние 24 часа. Затем запрос выбирает URI, для которых число обращений за последний час более чем в три раза превышает это усредненное число.
CREATE VIEW PageRequestsWithCount AS SELECT STREAM ROWTIME, uri, COUNT(*) OVER lastHour AS hourlyRate, COUNT(*) OVER lastDay / 24 AS hourlyRateLastDay FROM PageRequests WINDOW lastHour AS ( PARTITION BY uri RANGE INTERVAL ‘1’ HOUR PRECEDING) lastDay AS ( PARTITION BY uri RANGE INTERVAL ‘1’ DAY PRECEDING);
SELECT STREAM * FROM PageRequestsWithCount WHERE rate > hourlyRateLastDay * 3;
В отличие от предыдущего запроса, в котором использовался раздел GROUP BY для агрегации многих записей в одну сводную для каждого заданного промежутка времени, в данном запросе используется оконное (windowed) агрегатное выражение (агрегатная функция НАД окном, aggregate-function OVER window) для добавления к каждой строке аналитических значений. Поскольку в каждую строку добавляются статистические данные за последние час и день, не требуется накапливать пакет записей. Такой запрос можно использовать для постоянной поддержки списка "наиболее популярных страниц" своего сайта, а в коммерческих сайтах он может применяться для определения товаров, объемы продаж которых превышают норму.